AI Trainer
Problem
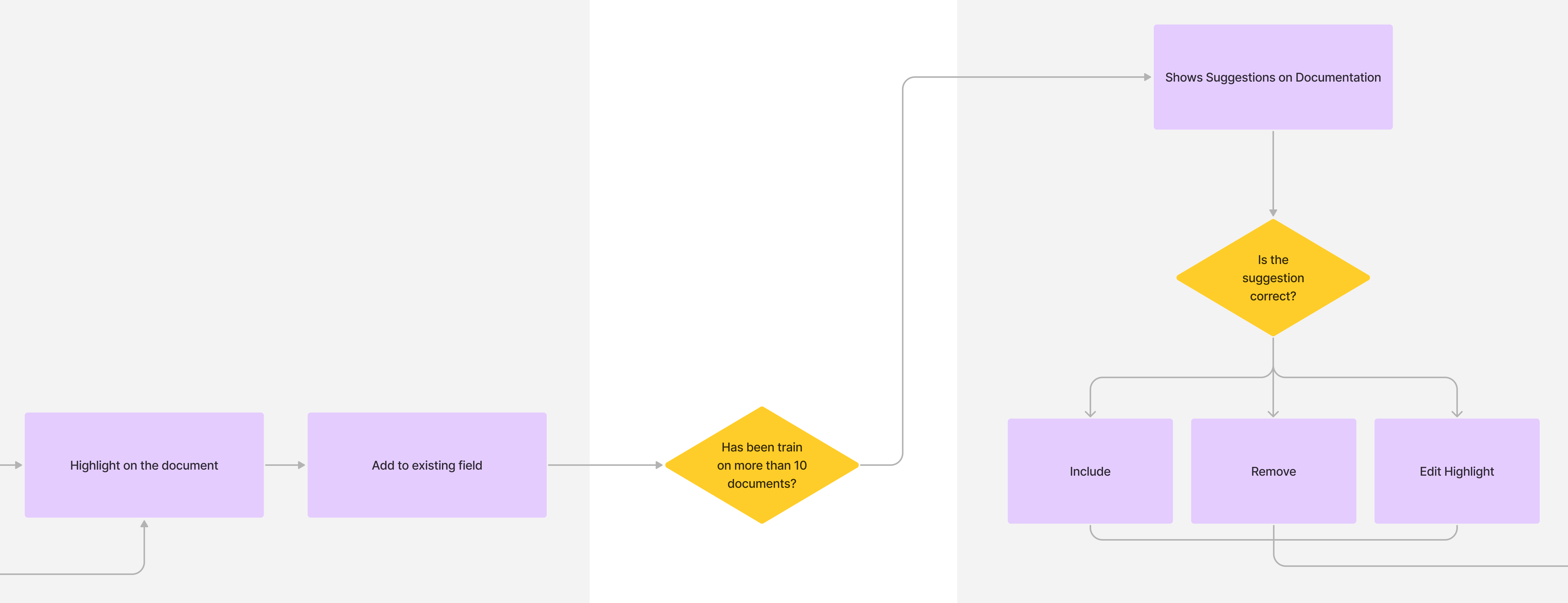
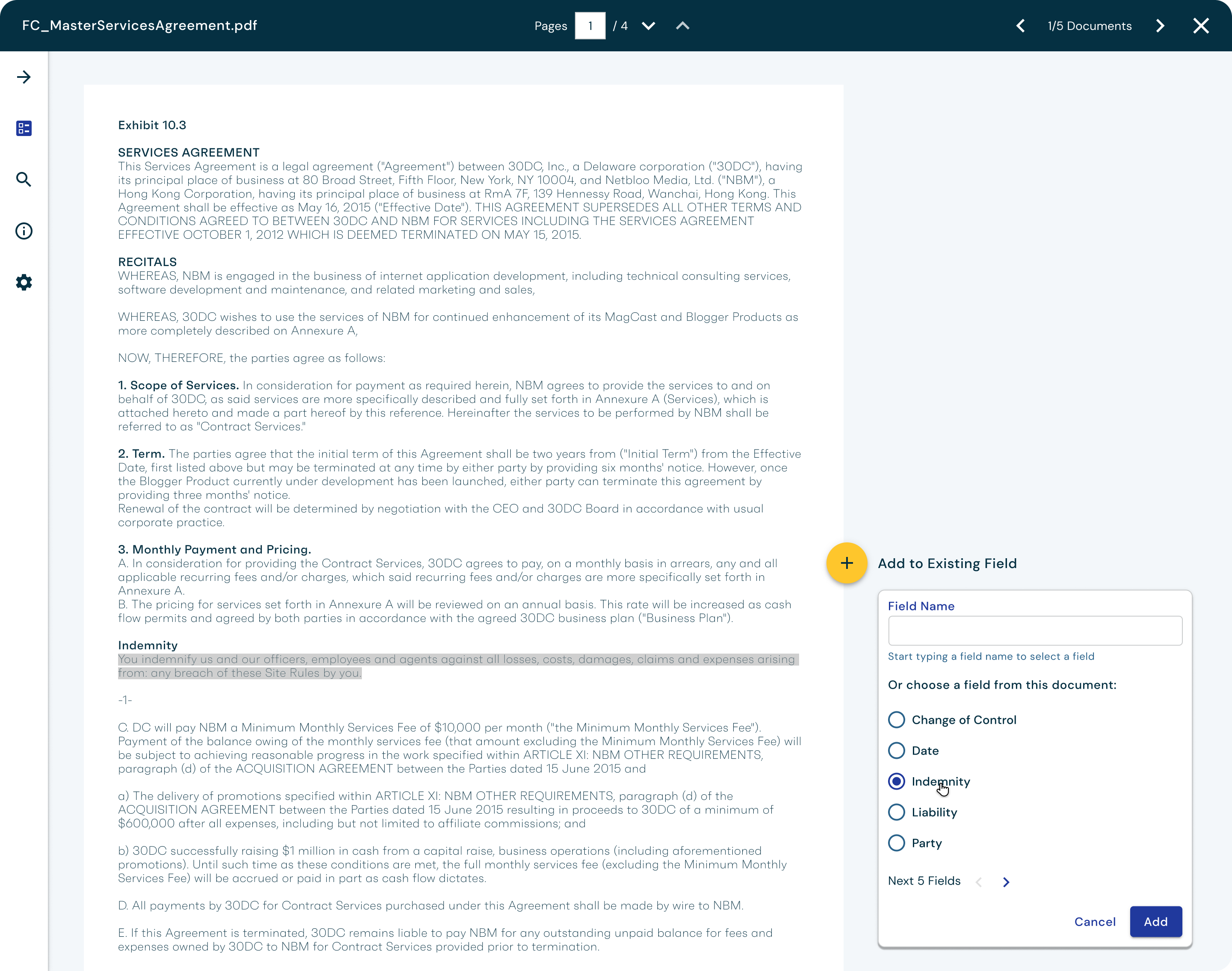
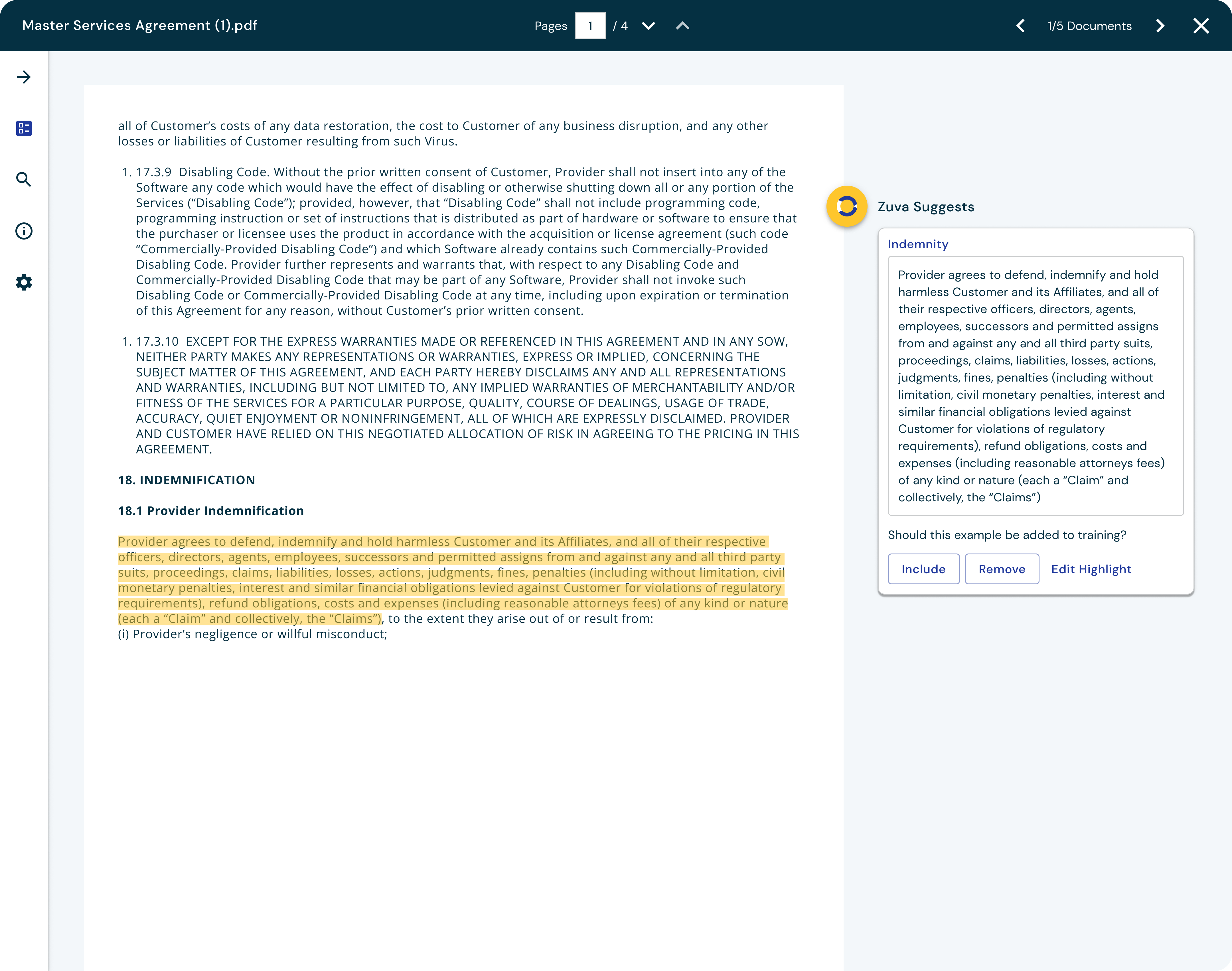
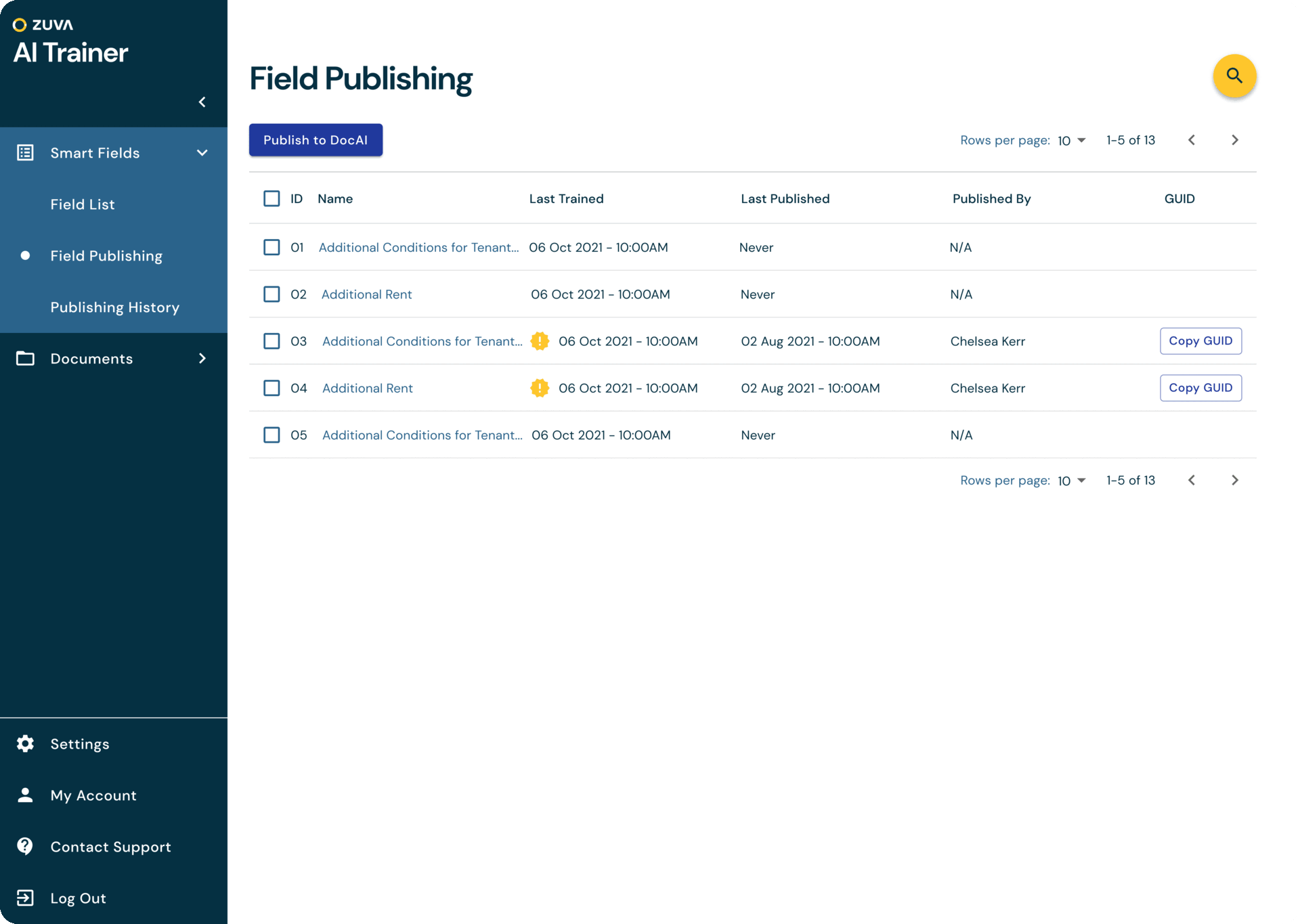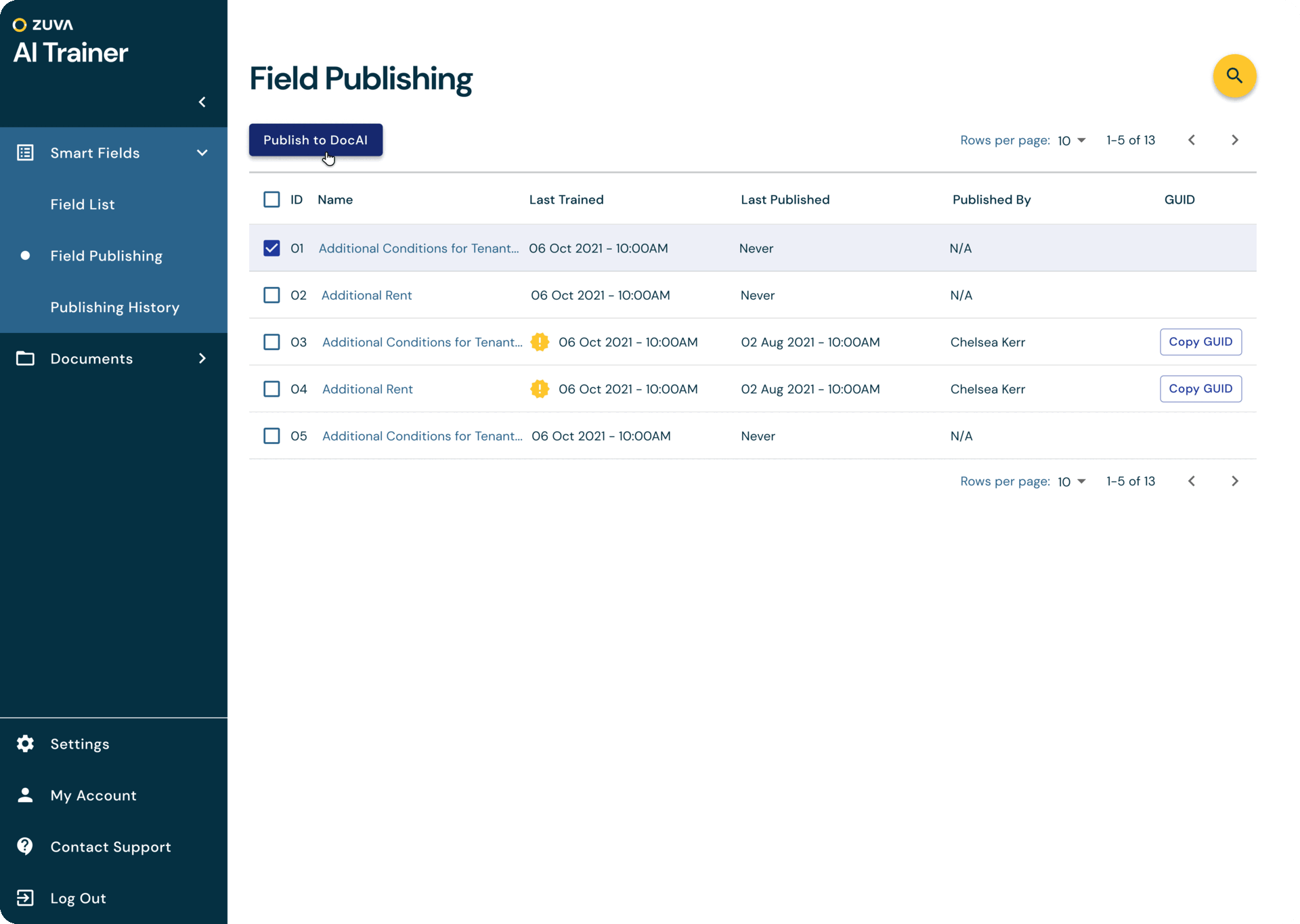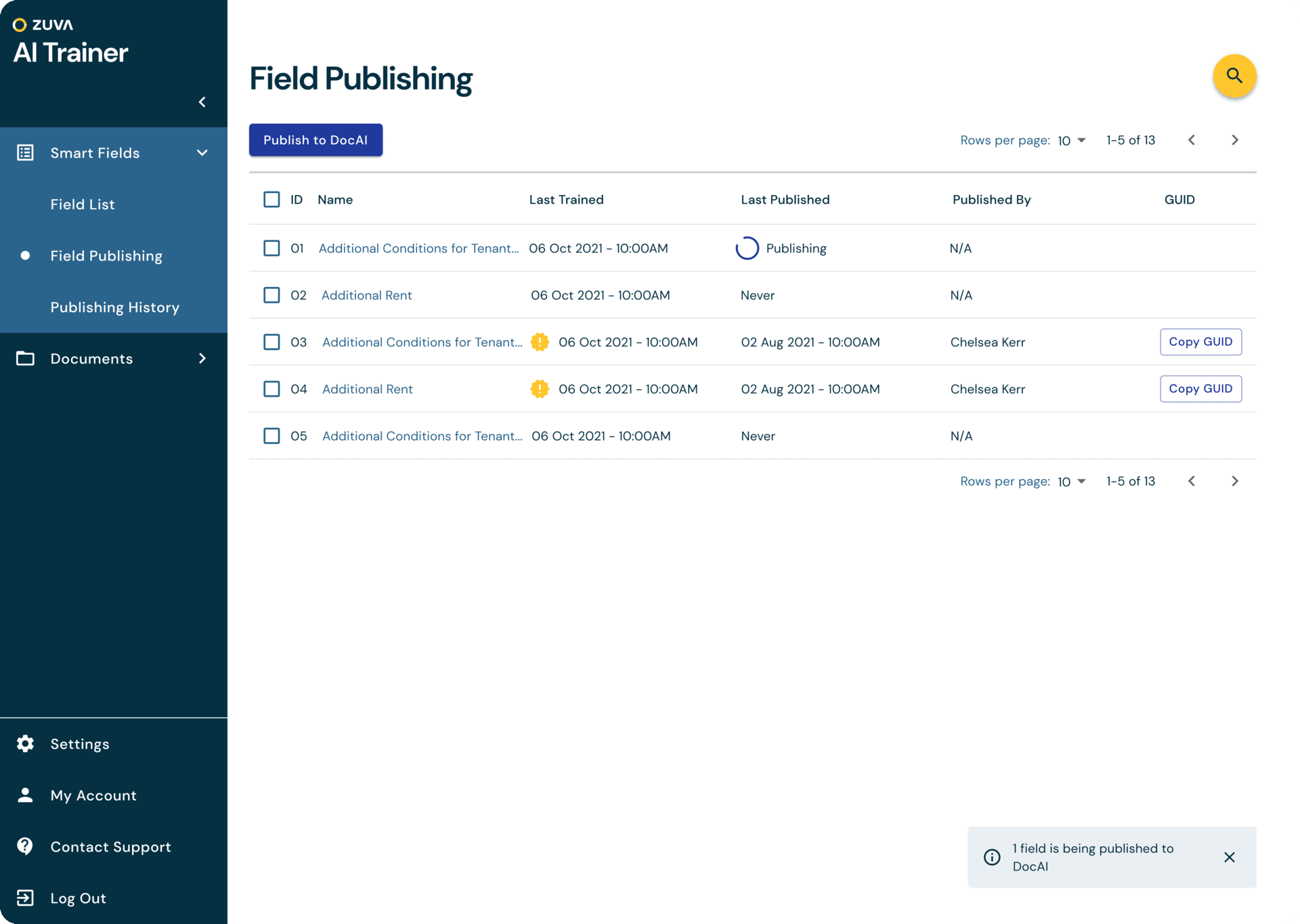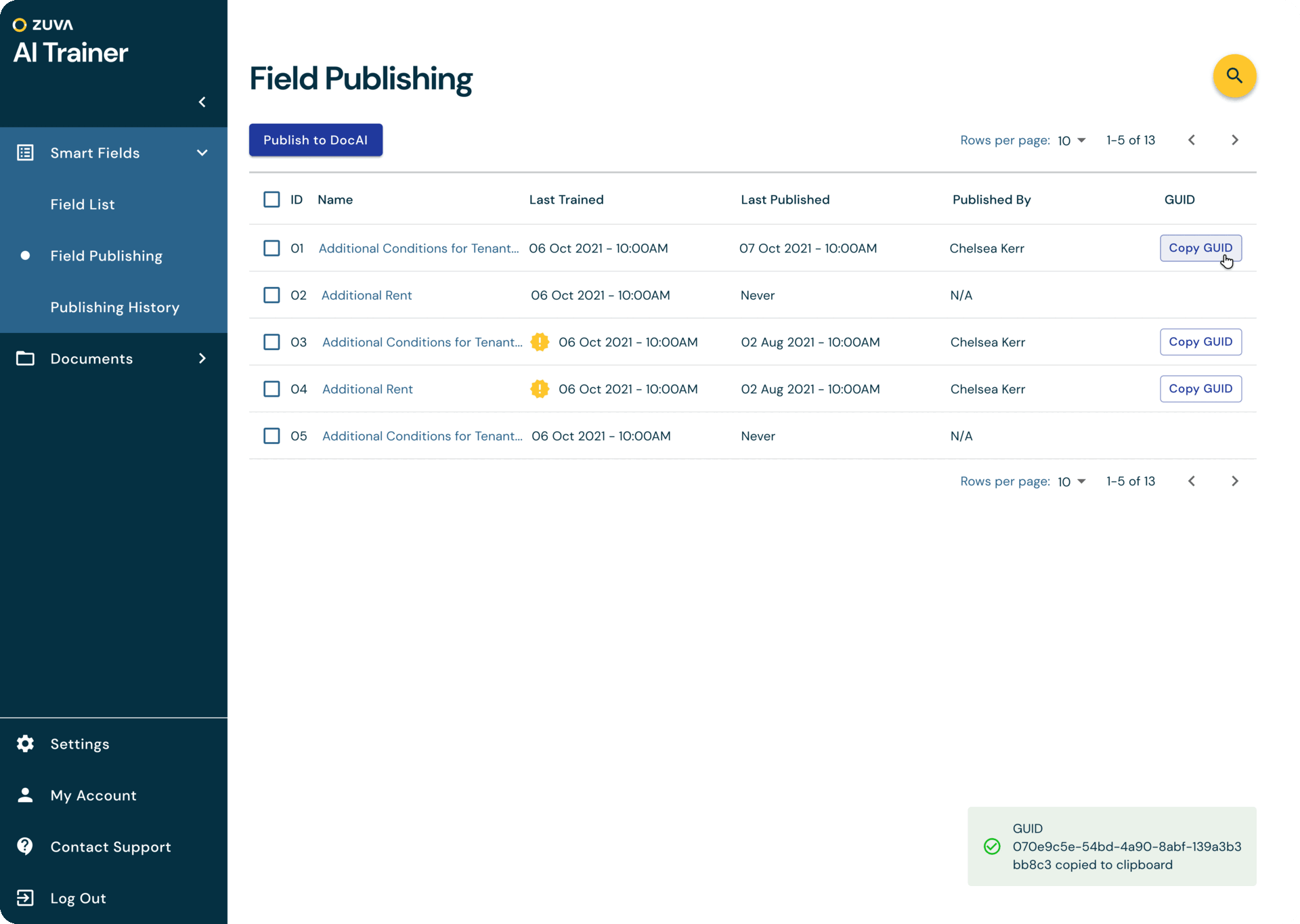
At Zuva, we offer customers over 1,300 AI fields that find different legal concepts in contracts and other documents. However, sometimes those built-in fields not find the exact data points the customers is looking for and they would like to be able to train their own AI fields to find what the information they need.
Role
Principal Product Designer
Timeline
3 months (Sep-Dec 2021)
Responsibilities
Design, product strategy, review and action on research